1. Introducing Unit 6: Genes and Gene Expression
In Unit 1 of this course, we devoted a tutorial to the structure and function of nucleic acids. Nucleic acids are the molecules of heredity, and they include DNA and RNA.
In this unit — Unit 6 — we’ll apply what we learned in Unit 1 to explain the biochemical nature of genes, and how genes (the units of heredity) get expressed in the phenotype (the observable appearance) of an organism.
On a cellular level, the basic idea of gene expression is that genetic information, in the form of DNA, gets converted into RNA, which provides instructions for assembling proteins. The conversion of DNA information into RNA is called transcription. The conversion of RNA information into the amino acid sequence that makes up the primary structure of a protein is called translation.
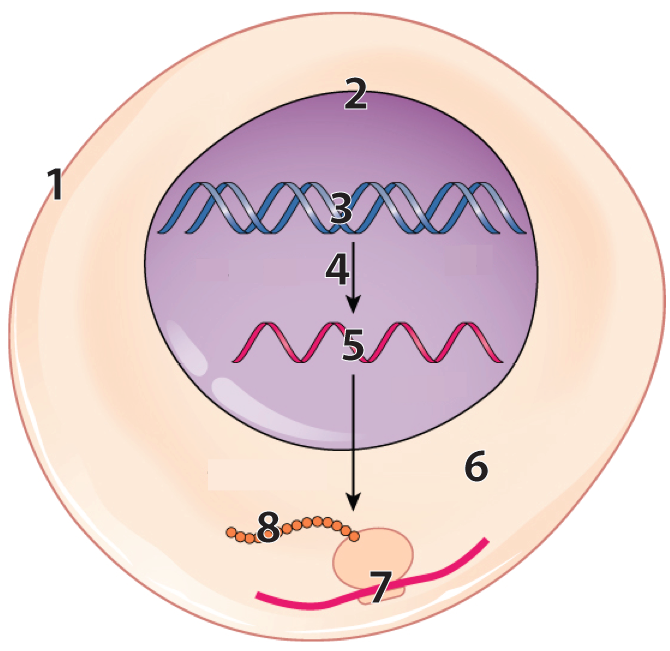 This diagram shows how gene expression works in a very simplified cell.
This diagram shows how gene expression works in a very simplified cell.
- Number 3 shows DNA in the nucleus (with 2 representing the nuclear membrane)
- Number 4 shows DNA being transcribed into RNA (5)
- Number 7 shows translation: A ribosome is translating RNA information (the red line) into a sequence of amino acids (8) which will fold up to become a protein.
While the image on the right shows a simplified eukaryotic cell, keep in mind that with some minor differences, the processes of transcription and translation occur in prokaryotic cells as well.
The flow of information from DNA to RNA to protein is such a key idea that it’s called the central dogma of molecular biology. Dogma means “authoritative idea,” and as an AP Bio student, you need to understand the central dogma well. It’s usually expressed as DNA makes RNA makes protein.
Because many teachers put Unit 6 ahead of unit 5, I’ll continue to define genetic terms as we encounter them (just as I did above with genes and phenotype).
The plan for this unit is to start by reviewing and deepening our understanding of DNA. We’ll follow that with tutorials that look at the details of transcription and translation. Then we’ll look at the specifics of how these processes work in prokaryotes, eukaryotes, and viruses. We’ll end by looking at how, in the past three or four decades, humans have learned to manipulate the workings of DNA and gene expression, creating the fields of biotechnology and genetic engineering.
2. Five more things to know about DNA
2a. Pyrimidines and Purines
In Unit 1, you learned about the monomers of nucleic acids, which are nucleotides. Nucleotides can be classified into two categories. Nucleotides with double-ring nitrogenous bases (like adenine and guanine) are called purines. Those with single-ring nitrogenous bases (thymine and cytosine) are called pyrimidines.
The four DNA nucleotides |
|
| Purines (bases with two nitrogen rings) | Pyrimidines (bases with one nitrogen ring) |
|
|
|
|
|
|
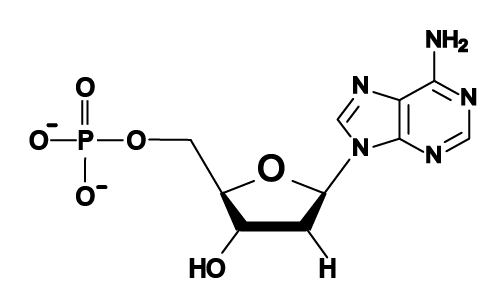
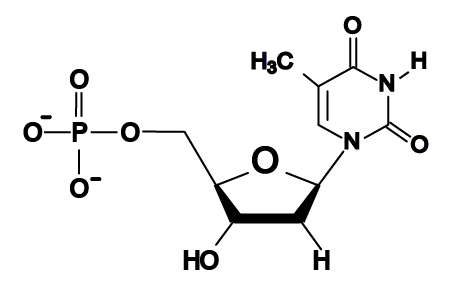
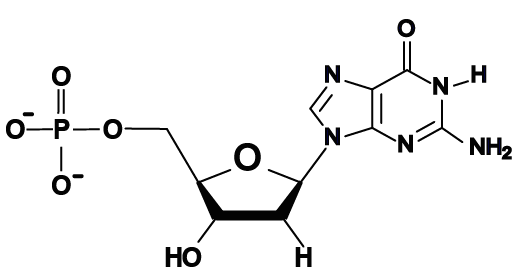
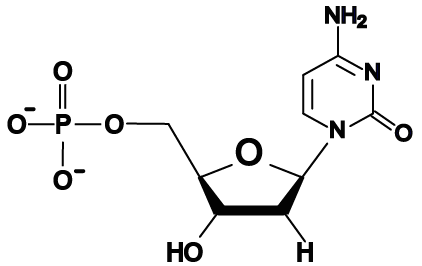
Why is this important? In the early 1950s, as scientists were racing to determine the structure of DNA, it was realized that the width of DNA could only accommodate a purine binding with a pyrimidine, as shown below.
Note that each base pair consists of a double-ring purine such as “A” binding with a single-ring pyrimidine such as “T.” A match between two purine bases would be too wide for the helix, and a match between two pyrimidines would be too narrow.
2b. Chargaff’s Rule: The evidence for A-T: C-G base pairing
In 1950, Swiss Biochemist Erwin Chargaff discovered that in any species, the amount of adenine matches the amount of thymine, and the amount of cytosine matches the amount of guanine. This came to be known as “Chargaff’s rule.”
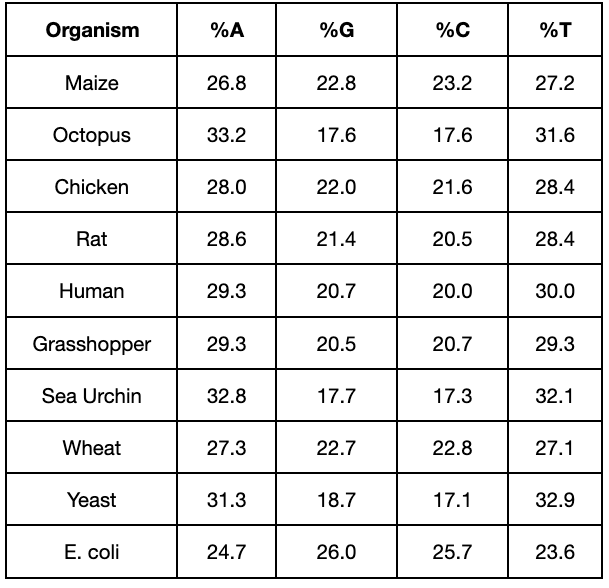
Chargaff’s rule enabled the discoverers of DNA’s structure to infer the specific base pairing that occurs in DNA. In other words, not only did a purine have to bind with a pyrimidine, but the match was specific: The purine guanine could only bind with the pyrimidine cytosine, and the purine adenine could only bind with the pyrimidine thymine.
As we discussed in Unit 1, the specificity of base-pairing is rooted in the chemical structure of the nitrogenous bases. On a molecular level, guanine and cytosine fit together and bind with each other with three hydrogen bonds. Similarly, adenine and thymine fit together and bind with each other with two hydrogen bonds.
| The dotted lines between complementary bases indicate hydrogen bonds | |
| Guanine-Cytosine | Adenine-Thymine |
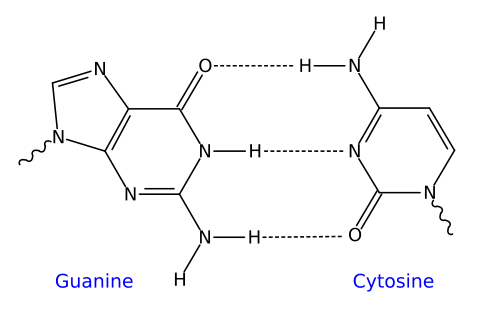 |
 |
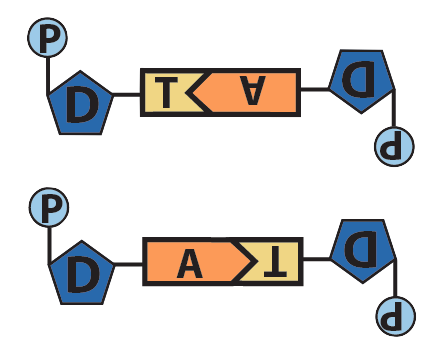
Though it’s not shown in the diagram above (and often not shown in published diagrams) complementarity between bases and hydrogen bond formation only happens when the nucleotides are positioned upside-down relative to one another, as shown below.
| Adenine and Thymine | Guanine and Cytosine |
 |
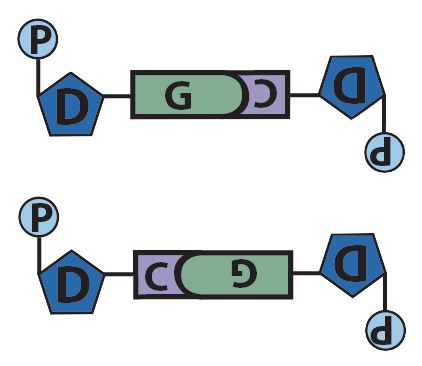 |
The result of this complementary base pairing is that DNA is typically double-stranded. Because the nucleotides in the two strands can form hydrogen bonds with one another only when they’re oriented upside-down relative to one another, the overall arrangement of the molecule is said to be antiparallel.
2c. How We Know that DNA is a Double Helix
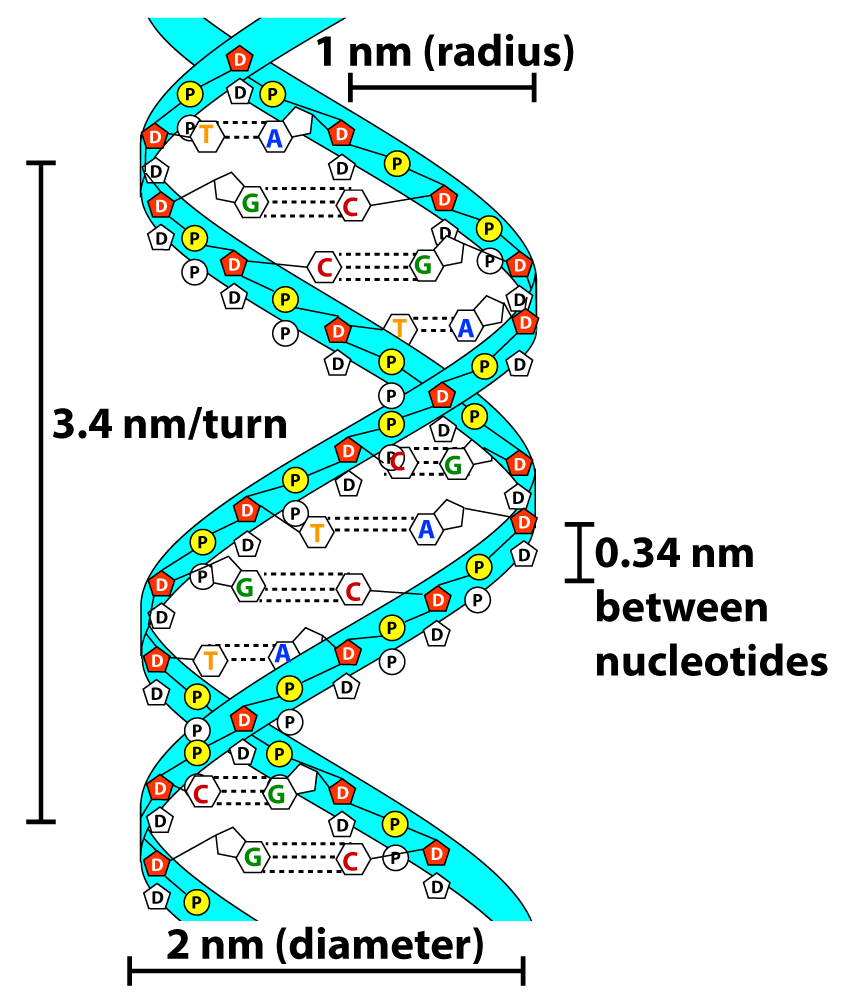
DNA’s double helical shape was determined by studies using a technique called X-ray diffraction. In X-ray diffraction, an X-ray photograph is taken of DNA, creating the image shown below on the left. Through some complex math, DNA’s structure could be interpreted as what’s shown on the right.
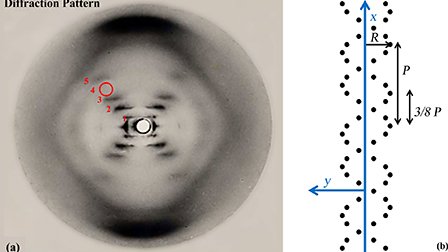
Note that this photograph was also the basis for determining the dimensions of DNA (shown above).
2d. Who were DNA’s discoverers?
James Watson and Francis Crick published a paper in Nature in April of 1953 describing DNA’s structure. Watson, Crick, and a third researcher (Maurice Wilkins) received the Nobel Prize for this discovery in 1962. However, a fourth scientist also deserves credit. Her name is Rosalind Franklin, and she took the photograph above and provided much of the data that Watson and Crick used to decipher DNA’s structure. But for at least two reasons, Franklin’s contribution is often overlooked. First, Franklin died in 1958, and the Nobel Prize is only awarded to living scientists (not posthumously). Second, Franklin was a pioneering female scientist working in what was, at the time, an even more sexist and male-dominated world than the one we live in today. There was so much drama in the relationship between Watson, Crick, Franklin, and Wilkins that a play was written about it. It’s called “Photograph 51” (named for the image above). It was written by Anna Zeigler. An audio-only version is available on SoundCloud.
If you want to read Watson and Crick’s 1953 paper, you can do so at Nature Scitable. Watson also wrote a book about the discovery of DNA called The Double Helix, which you can access as a pdf. To learn more about Franklin, read her biography on Wikipedia, or read Brenda Maddox’s Rosalind Franklin: The Dark Lady of DNA. Finally, the definitive history of the story of the discover of DNA’s structure is The Secret of Life, by Howard Markel. I highly recommend it!
2e. DNA’s Directionality
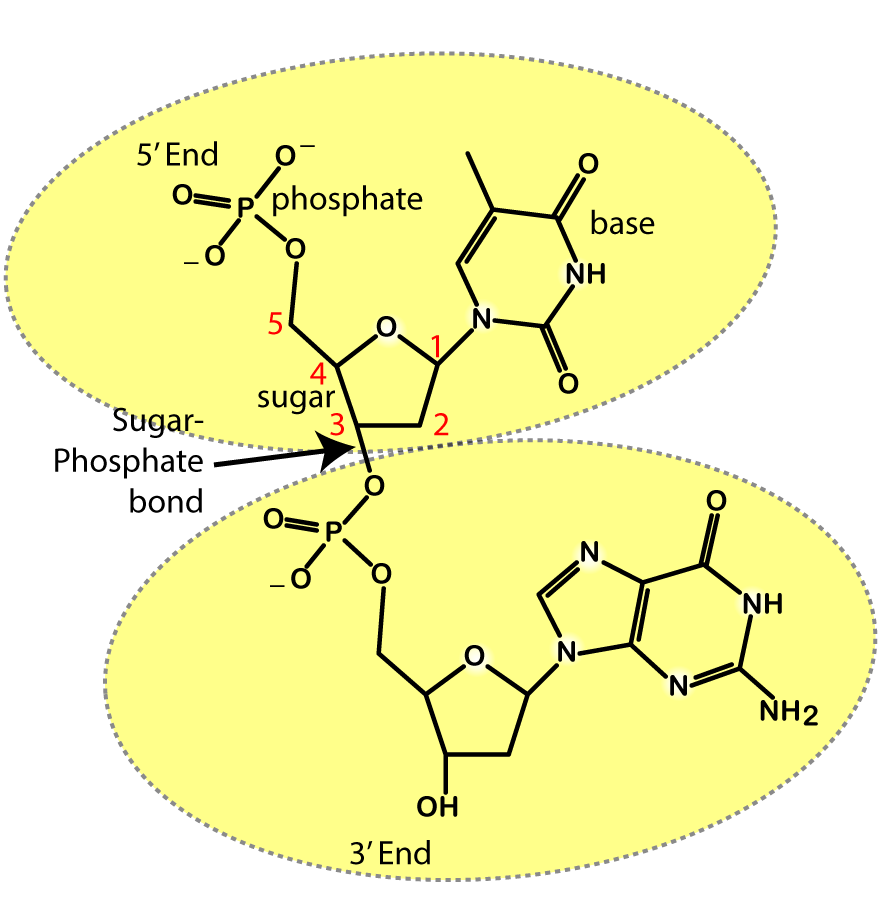 DNA is the substrate for many enzymatic reactions. During DNA replication and transcription, for example, enzymes ride along an exposed strand of DNA and synthesize new DNA (during replication) or RNA (during transcription) by adding new nucleotides to the growing daughter strand. In both cases, the enzymes can only add new nucleotides in one direction: the 3′ end.
DNA is the substrate for many enzymatic reactions. During DNA replication and transcription, for example, enzymes ride along an exposed strand of DNA and synthesize new DNA (during replication) or RNA (during transcription) by adding new nucleotides to the growing daughter strand. In both cases, the enzymes can only add new nucleotides in one direction: the 3′ end.
What does that mean? Look at the structural formula of the two DNA nucleotides that are connected by a sugar-phosphate bond to your right. A convention used by biochemists is to number the carbons in a sugar. Now look at the upper nucleotide, and find the # 1 carbon in deoxyribose. The # 1 carbon is the one that binds to the nitrogenous base. Now find the # 5 carbon: that’s the one that binds to a phosphate group. The # 3 carbon is the one that forms a sugar-phosphate bond with the next nucleotide.
The key thing to remember here is that during the synthesis of DNA or RNA, enzymes move in a 5′ to 3′ direction, always adding new nucleotides at the 3′ end.
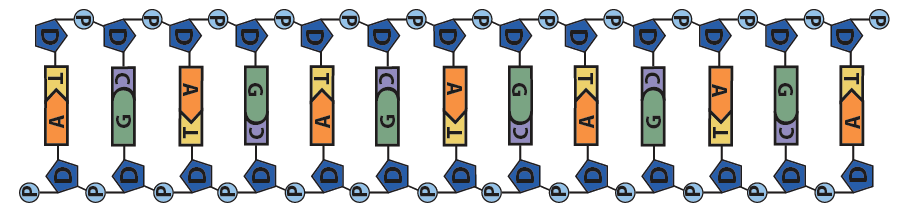
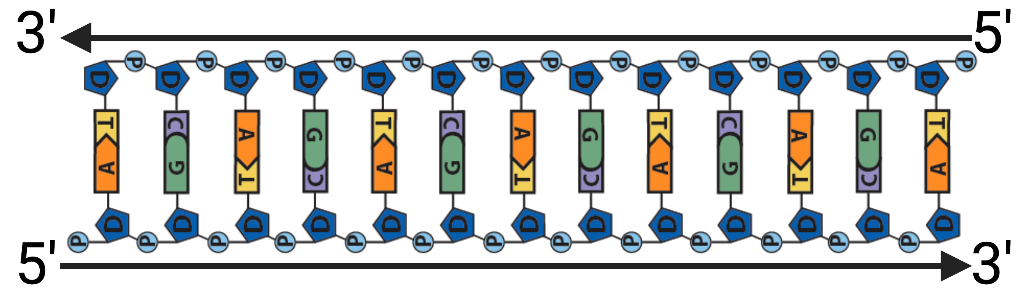
The diagram below shows DNA with the 5′ and 3′ ends shown on each strand. Note how the upper strand runs 5′ to 3′ in a right-to-left direction, whereas the lower strand runs 5′ to 3′ in a left-to-right direction. That’s really what’s meant by the term “antiparallel.”
3. DNA Fantastic!
My DNA, Fantastic Video will help you to review pretty much everything you need to know. To read the lyrics, click here.
3a. Original Video
Enjoy!
3b. DNA Fantastic Karaoke Challenge
Now sing it!
4. DNA Structure: Checking Understanding
To make sure you’ve mastered what’s above, study the flashcards and take the quiz below.
4a. Nucleic Acids Review Flashcards
[qdeck bold_text=”false” style=”width: 550px !important; min-height: 400px !important;” qrecord_id=”sciencemusicvideosMeister1961-Nucleic Acids Review Flashcards (v2.0)”]
[h]Nucleic Acids Review Flashcards
[q]Using the diagram below, describe the basic flow of information in cells.
[a]
DNA (3) is the molecule of heredity. DNA gets transcribed into RNA (5), which carries information to ribosomes (7), which translate information in RNA into protein (8).
[q json=”true” yy=”4″ unit=”1.Chemistry_of_Life” dataset_id=”AP_Bio_Flashcards_2022|1ed774e81a910″ question_number=”38″ topic=”1.5-6.Proteins_and_Nucleic_Acids”] Describe the biological importance of DNA and RNA.
[a] DNA is the molecule of heredity. It’s the informational part of the chromosomes that get passed from one generation to the next during reproduction, and from mother cells to daughter cells during growth and development.
While RNA is a hereditary molecule in some viruses, its key role is information transfer, as in messenger RNA. RNA can also act as an enzyme, catalyzing reactions.
[q json=”true” yy=”4″ unit=”1.Chemistry_of_Life” dataset_id=”AP_Bio_Flashcards_2022|1ecd453415110″ question_number=”39″ topic=”1.5-6.Proteins_and_Nucleic_Acids”] Name the monomer of nucleic acids and describe this monomer’s structure.
[a] The monomers of nucleic acids are nucleotides, which consist of a 5-carbon sugar (at 2), a phosphate group (at 1), and one of four nitrogenous bases (at 3). The phosphate group is connected to the 5’ carbon in the sugar, and the nitrogenous base is connected to the 1’ carbon.
[q]Describe how the monomers of RNA and DNA are different.
[a]In RNA, the sugar is ribose, and the bases are adenine, uracil, cytosine, and guanine. In DNA, the sugar is deoxyribose, and the bases are adenine, thymine, cytosine, and guanine.
[q]Use this diagram to identify the key parts of DNA
[a]1. Deoxyribose; 2. Phosphate groups; 3. sugar-phosphate bonds; 4. Nitrogenous bases; 5. An entire nucleotide; 6. Hydrogen bonds. 7. Sugar-phosphate backbone
[q json=”true” yy=”4″ unit=”1.Chemistry_of_Life” dataset_id=”AP_Bio_Flashcards_2022|1eb8c08b4bd10″ question_number=”41″ topic=”1.5-6.Proteins_and_Nucleic_Acids”] Describe the structure of DNA.
[a] DNA consists of two nucleotide strands. Within each strand, the nucleotides connect by sugar-phosphate bonds. The strands connect by hydrogen bonds between nitrogenous bases with complementary shapes: adenine bonds with thymine; cytosine binds with guanine. The binding requires that the nucleotides be oriented upside-down relative to one another. Hence, the two strands are antiparallel, with one strand running 5’ to 3’ in one direction, and the other running 5’ to 3’ in the opposite direction.
[q] Nucleic acids are life’s key information molecule. How do they store information?
[a] Nucleic acids store information in their sequence of nucleotides. That sequence can be translated into the primary structure of a protein, allowing information to become molecular structures that carry out specific functions (as in enzymes and other protein molecules).
[q] What are the base-pairing rules in DNA? Why are these rules important?
[a] The base-pairing rules allow for DNA to be accurately copied from one generation of organisms or cells to the next. The rules are A (adenine) binds with T (thymine) and C (cytosine) binds with G (guanine)
[x][restart]
[/qdeck]
4b. DNA, RNA, and Nucleotides Quiz
[qwiz random = “true” style=”width: 550px !important; min-height: 450px !important;” qrecord_id=”sciencemusicvideosMeister1961-DNA, RNA, and Nucleotides Quiz (v2.0)”]
[h] DNA, RNA, and Nucleotides: Checking Understanding
[i]
[q] When parents pass genes on to their offspring, they’re doing it through the transmission of [hangman].
[c]IEROQQ==[Qq]
[f]IEV4Y2VsbGVudCE=[Qq]
[q] To use an analogy from the kitchen, DNA provides a kind of [hangman] that cells follow by making two other types of molecules: one is another nucleic acid called [hangman] (shown at “5”); the second is [hangman] (a polymer of amino acids, shown at “8”).
[c]IHJlY2lwZQ==[Qq]
[f]IEV4Y2VsbGVudCE=[Qq]
[c]IFJOQQ==[Qq]
[f]IEdyZWF0IQ==[Qq]
[c]IHByb3RlaW4=[Qq]
[f]IEdvb2Qh[Qq]
[q] In multicellular animals like ourselves, DNA also guides the pattern of [hangman] by which a fertilized egg develops into a multicellular organism.
[c]IGRldmVsb3BtZW50[Qq]
[f]IENvcnJlY3Qh[Qq]
[q] In organisms, the nucleic acid [hangman] is the molecule of heredity. The only entities where RNA acts as the molecule of heredity are some (but not all) of the infectious particles known as [hangman].
[c]RE5B[Qq]
[c]IHZpcnVzZXM=[Qq]
[f]IEdvb2Qh[Qq]
[q] The monomers of nucleic acids are called [hangman].
[c]IG51Y2xlb3RpZGVz[Qq]
[f]IEdvb2Qh[Qq]
[q] The sugar in DNA (shown on the right at “2) is [hangman]. The sugar in RNA (shown on the left at “2”) is [hangman].
[c]IGRlb3h5cmlib3Nl[Qq]
[f]IENvcnJlY3Qh[Qq]
[c]IHJpYm9zZQ==[Qq]
[f]IENvcnJlY3Qh[Qq]
[q] Whereas DNA has the nitrogenous base thymine, RNA uses [hangman].
[c]IHVyYWNpbA==[Qq]
[f]IEdyZWF0IQ==[Qq]
[q] The three subparts of a nucleotide are a five carbon [hangman] (at “2”), a [hangman] base (at “4”) , and a [hangman] group (at “1”).
[c]IHN1Z2Fy[Qq]
[f]IEdyZWF0IQ==[Qq]
[c]IG5pdHJvZ2Vub3Vz[Qq]
[f]IEV4Y2VsbGVudCE=[Qq]
[c]IHBob3NwaGF0ZQ==[Qq]
[f]IEdvb2Qh[Qq]
[q] The flow of information in a cell starts with [hangman] in the cell’s nucleus. Then, the information in DNA is transformed into [hangman] which takes that information out to the cytoplasm. There, the information gets transformed into [hangman].
[c]IEROQQ==[Qq]
[f]IEV4Y2VsbGVudCE=[Qq]
[c]IFJOQQ==[Qq]
[f]IEdyZWF0IQ==[Qq]
[c]IHByb3RlaW4=[Qq]
[f]IEdvb2Qh[Qq]
[q] In the diagram below, DNA is at
[textentry single_char=”true”]
[c]ID M=[Qq]
[f]IEV4Y2VsbGVudDogJiM4MjIwOzMmIzgyMjE7IGlzIEROQS4=[Qq]
[c]ICo=[Qq]
[f]IEhlcmUmIzgyMTc7cyBhIGhpbnQ6IEROQSBpcyBhIGRvdWJsZSBoZWxpeC4=[Qq]
[c]IEVudGVyIGxldHRlcg==[Qq]
[q] In the diagram below, RNA that has just been transcribed is at
[textentry single_char=”true”]
[c]ID U=[Qq]
[f]IE5pY2U6ICYjODIyMDs1JiM4MjIxOyBpcyBSTkEgdGhhdCBpcyBzdGlsbCBpbiB0aGUgbnVjbGV1cywgYW5kIGhhcyBqdXN0IGJlZW4gdHJhbnNjcmliZWQu[Qq]
[c]ICo=[Qq]
[f]IEhlcmUmIzgyMTc7cyBhIGhpbnQ6IFJOQSBpcyBmb3VuZCBpbiBib3RoIHRoZSBudWNsZXVzIGFuZCB0aGUgY3l0b3BsYXNtLiBGaW5kIHRoZSBSTkEgaW4gdGhlIG51Y2xldXMu[Qq]
[c]IEVudGVyIGxldHRlcg==
Cgo=Ww==
[l]deoxyribose
[fx] No, that’s not correct. Please try again.
[f*] Good!
[l]hydrogen bonds
[fx] No, that’s not correct. Please try again.
[f*] Excellent!
[l]nitrogenous base
[fx] No. Please try again.
[f*] Great!
[l]nucleotide
[fx] No. Please try again.
[f*] Correct!
[l]phosphate group
[fx] No. Please try again.
[f*] Good!
[l]sugar-phosphate backbone
[fx] No. Please try again.
[f*] Great!
[l]sugar-phosphate bond
[fx] No, that’s not correct. Please try again.
[f*] Good!
[q labels = “top”]
[l]hydrogen bond
[fx] No. Please try again.
[f*] Good!
[l]covalent bond
[fx] No, that’s not correct. Please try again.
[f*] Excellent!
[q hotspot_user_interaction=”label_prompt” show_hotspots=”” ] DNA structure. Click on the numbers.
Excellent! “1” is deoxyribose.
Nice! “2” represents phosphate groups
Way to go. “3” represents sugar-phosphate bonds.
Good job. “4” represents nitrogenous bases.
Nice! “5” represents a nucleotide.
Great! “6” represents hydrogen bonds.
Good work! “7” represents the sugar phosphate backbones.
[q hotspot_user_interaction=”label_prompt” show_hotspots=””] Nucleotides: click on the numbers
Nice! “1” is a phosphate group.
Yes! “2” is a nitrogenous base.
Awesome. “2” is deoxyribose.
[q]The central dogma of molecular genetics is DNA makes ____ makes protein
[hangman]
[c]Uk5B[Qq]
[f]R2VuaXVzISBUaGUgY2VudHJhbCBkb2dtYSBvZiBtb2xlY3VsYXIgZ2VuZXRpY3MgaXMgRE5BIG1ha2VzIA==Uk5BIG1ha2VzIHByb3RlaW4=
Cg==[Qq][q]In DNA, the orientation of the two complementary strands is
[hangman]
[c]YW50aS1wYXJhbGxlbA==[Qq]
[f]TmljZSEgSW4gRE5BLCB0aGUgb3JpZW50YXRpb24gb2YgdGhlIHR3byBjb21wbGVtZW50YXJ5IHN0cmFuZHMgaXMgYW50aS1wYXJhbGxlbA==
Cg==[Qq][q]Adenine is complementary to
[hangman]
[c]dGh5bWluZQ==[Qq]
[f]R29vZCBqb2IuIEFkZW5pbmUgaXMgY29tcGxlbWVudGFyeSB0byA=dGh5bWluZQ==
Cg==[Qq][q]Cytosine is complementary to
[hangman]
[c]Z3VhbmluZQ==[Qq]
[f]WWVhaCEgQ3l0b3NpbmUgaXMgY29tcGxlbWVudGFyeSB0byBndWFuaW5l[Qq]
[q]In a DNA nucleotide, the sugar is
[hangman]
[c]ZGVveHlyaWJvc2U=[Qq]
[f]R29vZCBqb2IhIEluIGEgRE5BIG51Y2xlb3RpZGUsIHRoZSBzdWdhciBpcyA=ZGVveHlyaWJvc2U=
Cg==[Qq]
[q]In the diagram of a DNA molecule below, which number is pointing to a phosphate group?
[c]IDE=[Qq]
[c]IDI=[Qq]
[c]ID M=[Qq]
[c]IDQ=[Qq]
[c]IDU=[Qq]
[c]IDY=[Qq]
[c]IDc=[Qq]
[c]IDg=[Qq]
[c]IDk=[Qq]
[f]Tm8uIE51bWJlciAxIGluZGljYXRlcyB0aGUgc3VnYXItcGhvc3BoYXRlIGJhY2tib25lLg==[Qq]
[f]Tm8uIE51bWJlciAyIGluZGljYXRlcyBhIHN1Z2FyLXBob3NwaGF0ZSBib25kLg==[Qq]
[f]WWVzLiBOdW1iZXIgMyBpbmRpY2F0ZXMgYSBwaG9zcGhhdGUgZ3JvdXAu[Qq]
[f]Tm8uIE51bWJlciA0IGluZGljYXRlcyBkZW94eXJpYm9zZS4=
[f]Tm8uIE51bWJlciA1IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZXMgYWRlbmluZQ==Lg==[Qq]
[f]Tm8uIE51bWJlciA2IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZXMgdGh5bWluZQ==Lg==[Qq]
[f]Tm8uIE51bWJlciA3IGluZGljYXRlcyBoeWRyb2dlbiBib25kcy4=[Qq]
[f]Tm8uIE51bWJlciA4IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZSA=Y3l0b3NpbmU=Lg==
[f]Tm8uIE51bWJlciA5IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZSA=Z3VhbmluZQ==Lg==[Qq]
[q]During DNA replication, each parent strand serves as a _________ for the synthesis of a new strand
[c]bW9kZWw=[Qq]
[c]bW9sZA==[Qq]
[c]dGVtcG xhdGU=[Qq]
[c]Zm9ybQ==[Qq]
[f]Tm8uIOKAnE1vZGVs4oCdIGRvZXNu4oCZdCBxdWl0ZSB3b3JrLCBiZWNhdXNlIHRoZSBuZXcgRE5BIGlzIGNvbXBsZW1lbnRhcnkgdG8gdGhlIHBhcmVudCBzdHJhbmQuIFNlZSBpZiB5b3UgY2FuIGZpbmQgYSBtb3JlIGFjY3VyYXRlIGRlc2NyaXB0aW9uIG9mIHRoZSByZWxhdGlvbnNoaXAgYmV0d2VlbiB0aGUgcGFyZW50IHN0cmFuZCBhbmQgdGhlIG5ldyBzdHJhbmQu[Qq]
[f]IE5vLiDigJxNb2xk4oCdIGlzIHZlcnkgY2xvc2UsIGJ1dCBmaW5kIGEgbW9yZSB3aWRlbHkgdXNlZCB0ZXJtIHRvIGRlc2NyaWJlIHRoZSByb2xlIHRoYXQgdGhlIHBhcmVudCBzdHJhbmQgcGxheXMgc3RyYW5kLg==[Qq]
[f]WWVzLiBEdXJpbmcgRE5BIHJlcGxpY2F0aW9uLCBlYWNoIHBhcmVudCBzdHJhbmQgc2VydmVzIGFzIGEgdGVtcGxhdGUgZm9yIHRoZSBzeW50aGVzaXMgb2YgYSBuZXcgc3RyYW5kLg==[Qq]
[f]Tm8uIOKAnEZvcm3igJ0gZG9lc27igJl0IHF1aXRlIHdvcmssIGJlY2F1c2UgdGhlIG5ldyBETkEgaXMgY29tcGxlbWVudGFyeSB0byB0aGUgcGFyZW50IHN0cmFuZC4gU2VlIGlmIHlvdSBjYW4gZmluZCBhIG1vcmUgYWNjdXJhdGUgZGVzY3JpcHRpb24gb2YgdGhlIHJlbGF0aW9uc2hpcCBiZXR3ZWVuIHRoZSBwYXJlbnQgc3RyYW5kIGFuZCB0aGUgbmV3IHN0cmFuZC4=
Cg==[Qq]
[q labels = “top”]
[l]RNA
[fx] No, that’s not correct. Please try again.
[f*] Great!
[l]translation of RNA to protein
[fx] No, that’s not correct. Please try again.
[f*] Correct!
[l]DNA
[fx] No, that’s not correct. Please try again.
[f*] Excellent!
[l]cell membrane
[fx] No. Please try again.
[f*] Excellent!
[l]cytoplasm
[fx] No, that’s not correct. Please try again.
[f*] Good!
[l]protein
[fx] No, that’s not correct. Please try again.
[f*] Good!
[l]transcription of DNA to RNA
[fx] No, that’s not correct. Please try again.
[f*] Great!
[l]nuclear membrane
[fx] No, that’s not correct. Please try again.
[f*] Excellent!
[q]In the diagram of a DNA molecule below, which number represents hydrogen bonds?
[c]IDE=[Qq]
[c]IDI=[Qq]
[c]IDM=[Qq]
[c]IDQ=[Qq]
[c]IDU=[Qq]
[c]IDY=[Qq]
[c]ID c=[Qq]
[c]IDg=[Qq]
[c]IDk=[Qq]
[f]Tm8uIE51bWJlciAxIGluZGljYXRlcyB0aGUgc3VnYXItcGhvc3BoYXRlIGJhY2tib25lLg==[Qq]
[f]Tm8uIE51bWJlciAyIGluZGljYXRlcyBhIHN1Z2FyLXBob3NwaGF0ZSBib25kLg==[Qq]
[f]WWVzLiBOdW1iZXIgMyBpbmRpY2F0ZXMgYSBwaG9zcGhhdGUgZ3JvdXAu[Qq]
[f]Tm8uIE51bWJlciA0IGluZGljYXRlcyBkZW94eXJpYm9zZS4=
[f]Tm8uIE51bWJlciA1IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZXMgYWRlbmluZQ==Lg==[Qq]
[f]Tm8uIE51bWJlciA2IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZXMgdGh5bWluZQ==Lg==[Qq]
[f]WWVzLiBOdW1iZXIgNyBpbmRpY2F0ZXMgaHlkcm9nZW4gYm9uZHMu[Qq]
[f]Tm8uIE51bWJlciA4IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZSA=Y3l0b3NpbmU=Lg==
[f]Tm8uIE51bWJlciA5IGluZGljYXRlcyB0aGUgbml0cm9nZW5vdXMgYmFzZSA=Z3VhbmluZQ==Lg==[Qq]
[q]The bonds that connect complementary nucleotides are [hangman] bonds.
[c]aHlkcm9nZW4=
Cg==W2FdQXdlc29tZSEgVGhlIGJvbmRzIHRoYXQgY29ubmVjdCBjb21wbGVtZW50YXJ5IG51Y2xlb3RpZGVzIGFyZSA=aHlkcm9nZW4=IGJvbmRzLg==
[Qq][q]The process shown below is
[c]dHJhbnNjcmlwdGlvbg==[Qq]
[c]dHJhbnNsYXRpb24=[Qq]
[c]cmVwbGlj YXRpb24=[Qq]
[f]Tm8uIFRyYW5zY3JpcHRpb24gaXMgbWFraW5nIFJOQSBmcm9tIEROQS4gVGhlIHByb2Nlc3MgYWJvdmUgc2hvd3MgdGhlIGNvcHlpbmcgb2YgRE5BLiBXaGF0JiM4MjE3O3MgdGhhdCBjYWxsZWQ/[Qq]
[f]Tm8uIFRyYW5zbGF0aW9uIGlzIG1ha2luZyBwcm90ZWluLiBUaGUgcHJvY2VzcyBhYm92ZSBzaG93cyB0aGUgY29weWluZyBvZiBETkEuIFdoYXQmIzgyMTc7cyB0aGF0IGNhbGxlZD8=[Qq]
[f]WWVzLiBUaGUgcHJvY2VzcyBzaG93biBhYm92ZSDigJMgY29weWluZyBETkEg4oCTIGlzIGtub3duIGFzIHJlcGxpY2F0aW9uLg==[Qq]
[x]
[restart]
[/qwiz]
5. What’s next?
Proceed to Topic 6.2: DNA Replication (the next tutorial in AP Bio Unit 6)