1. Introduction: DNA and RNA are life’s molecules of information
Nucleic acids — DNA and RNA — are the fourth class of macromolecules.
1a. DNA Overview
DNA stands for deoxyribonucleic acid. It’s the molecule of heredity. It’s the stuff that genes are made of.
How does heredity work? Whether you’re a lizard, an orchid, or a bacterial cell, heredity works through the transmission of DNA from one generation to the next. DNA is chemically encoded information. In much the same way that the computer that you’re using is following instructions from a computer program and translating those instructions into letters and images on the screen, the cells that make up every organism follow DNA instructions that were sent to them from their parents (or parent, in the case of asexually reproducing organisms). Turning to a different analogy, you can think of the instructions in DNA as recipes. Cells read the DNA recipe and respond by making two other types of molecules: RNAs and proteins. These molecules, in turn, control cellular activities.
In multicellular beings like ourselves, DNA also guides the pattern of development by which a fertilized egg develops into a multicellular organism, a complex assembly of trillions of interdependent specialized cells, each cooperating so that our DNA can successfully be passed on to the next generation. In language-using, sapient beings like ourselves, we imbue our lives with additional meaning, but for the 3.8 or so billion years before humanity’s arrival on Earth, passing on DNA was all that life was about.
1b. RNA Overview
RNA stands for ribonucleic acid. RNA is also an informational molecule, but except for a few viruses where RNA is the hereditary molecule, RNA usually plays a different role than DNA, acting as an intermediate between the DNA that we inherit, and the protein that makes us up.
Let’s think of this about a specific trait. About 1 in every 2500 babies born to North Americans of European ancestry are born with a disease called cystic fibrosis. Cystic fibrosis involves the buildup of thick, sticky mucus in the lungs and other organs. This causes problems with breathing and sets the stage for chronic bacterial infections. There are other effects throughout the body, and the overall result is a significantly shortened lifespan.
The gene for cystic fibrosis codes for a defective transport protein in cell membranes. In a child who inherits the disease, the defective DNA instructions are in the nucleus (“2”) of every one of their cells, encoded within their DNA (at “3”). In the cells that make up this child’s lungs (where cystic fibrosis has its most significant effects) that DNA is transcribed into RNA, shown at “5.” That RNA leaves the nucleus and makes its way to the cytoplasm (“6”). In the cytoplasm, the information in the RNA is translated into protein (“8”) by a molecular machine called a ribosome (“7”). That protein, however, because it’s the product of a defective DNA recipe, won’t work correctly. When it makes its way to the cell membrane (“1”), it won’t correctly perform its function (which is to allow chloride ions to pass through the membrane). The accumulation of chloride in the cell has the effect of drawing water away from the cell’s exterior. This causes any mucus that’s been secreted from that cell to become thick, resulting in the symptoms of cystic fibrosis. As we’ll see again and again in this course, biology is all about information flow, and one of the key flows is the one that moves information from DNA to RNA to protein.
Unlike DNA, however, RNA’s role in cells is not strictly informational. RNA, like protein, can also be a molecule of action, similar to enzymes in its ability to interact with other molecules in a variety of ways, including catalyzing the formation of chemical bonds. For example, the ribosome shown at the right is made primarily of RNA, and it’s capable of reading an RNA message, and then taking amino acids and covalently bonding them together to form proteins. Other types of RNA play key roles in controlling the expression of DNA (such as when DNA information gets transcribed into RNA, and when that RNA information gets translated into proteins). For example, people with cystic fibrosis have compromised lung function, but their brains, bones, and muscles work as well as anyone else’s. It’s only in certain tissues that the defective DNA has its effect.
Because RNA has dual capabilities as both information and action, it’s a strong candidate for having served as part of the first living systems that originated about 3.8 billion years ago, when life first began — an amazing topic that we’ll explore when we learn about the origin of life.
2. The Monomers of Nucleic Acids are Nucleotides
In our tutorial about carbohydrates, I introduced the numbering system that biochemists use to refer to specific carbon atoms within a monosaccharide. If you need to, you can review that now (because I’m about to use it).
Both RNA and DNA are composed of monomers called nucleotides. The nucleotides that make up RNA and DNA have the same overall structure, but also a few differences.
| An RNA nucleotide | A DNA nucleotide |
 |
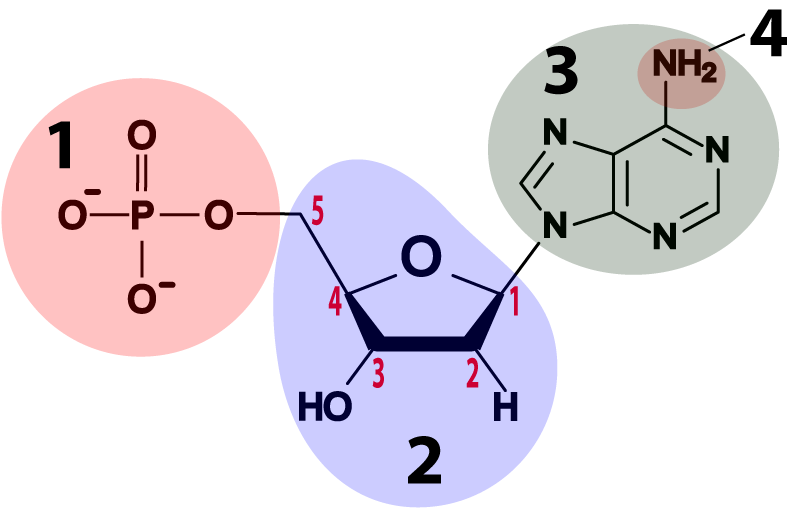 |
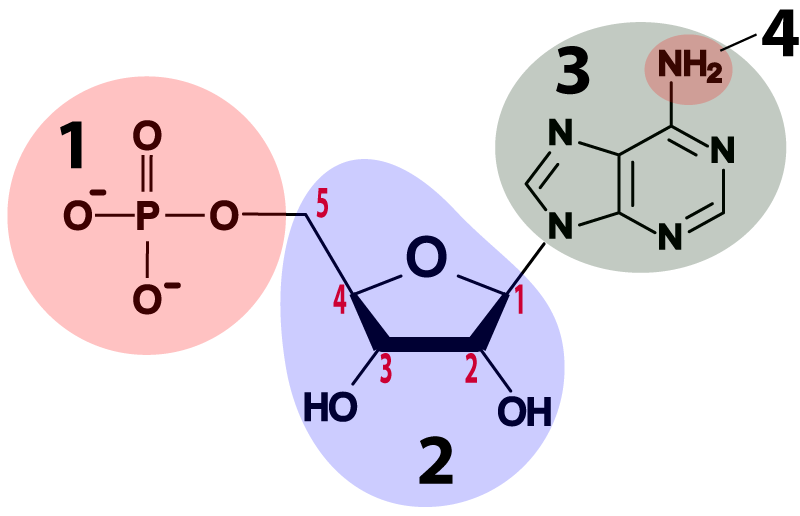
- DNA and RNA nucleotides are built around 5-carbon sugars (see region “2” in the table above). Remember that in the type of structural formula shown above the carbon atoms are implied: you have to imagine them at every angle vertex where an element isn’t specified (such as N or P). The sugar in an RNA nucleotide (the one on the left) is called ribose. The sugar in DNA is deoxyribose. If you look at the sugars, you can see how these names work. Ribose has hydroxyl groups (—OH) attached to its 3′ and 2′ carbons. In deoxyribose, the 2′ carbon has a hydrogen atom in place of the hydroxyl group. With one less oxygen, the name changes from ribose to deoxyribose.
- Attached to the 5′ carbon in both deoxyribose and ribose is a phosphate group (at “1”). The phosphate group is what makes these molecules acidic (the “A” in both DNA and RNA stands for “acid”). The negative charges on the oxygens are what’s left after protons have been donated to the surrounding solution.
- Attached to the 1′ carbon is one of four nitrogenous bases. They’re bases because they have an amino group attached to them (at “4”), and that amino group absorbs protons from a solution, raising the pH. They’re nitrogenous because they have a lot of nitrogen atoms. Some of these nitrogenous bases have two nitrogen rings (like adenine, shown below), but some have one. We’ll see why that’s important below.
- The bases in DNA are adenine, thymine, cytosine, and guanine, represented by the letters A, T, C, and G.
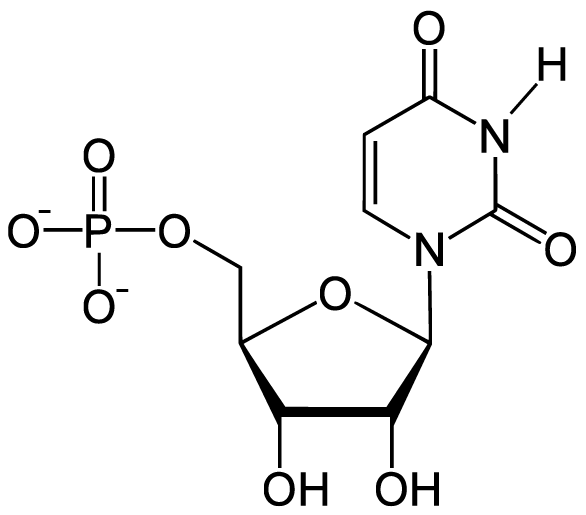
- The bases in RNA are adenine, uracil, cytosine, and guanine, represented by the letters A, U, C, and G.
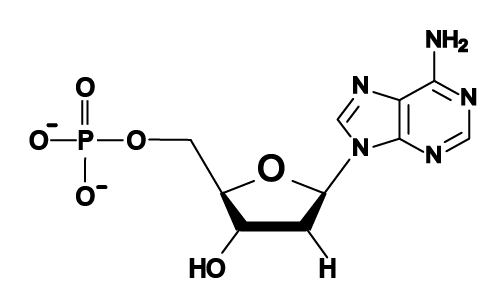
Here are the four DNA nucleotides. If you’re in AP Biology, don’t spend any time memorizing the structural formulas. If you’re in a college course, check with your instructor. You should note that adenine and guanine have nitrogenous bases with two nitrogen rings, while thymine and cytosine have a single ring.
The four DNA nucleotides |
|
| Bases with two nitrogen rings | Bases with one nitrogen ring |
|
|
|
|
|
|
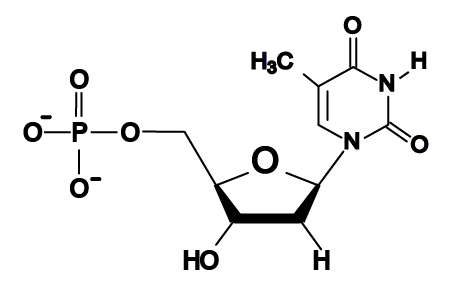
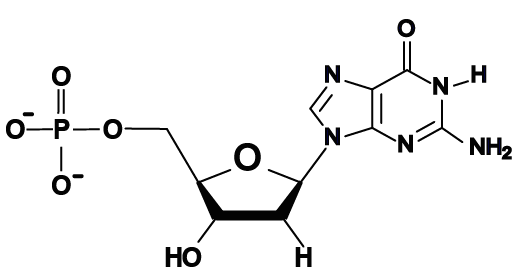
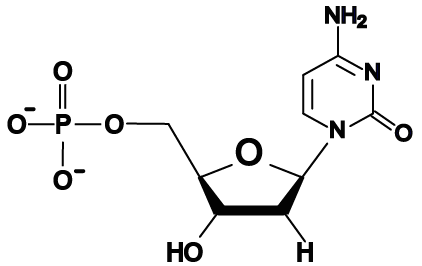
Here, for comparison, is an RNA nucleotide with uracil. Note the similarity between the uracil nitrogenous base and the nitrogenous base in thymine.
In what follows, we’ll learn
- how the nitrogenous bases in nucleic acids allow them to play their informational role, and
- how monomers get combined into DNA and RNA polymers,
But first, let’s consolidate our understanding with a quiz.
3. DNA, RNA, and Nucleotides Checking Understanding
[qwiz random = “true” qrecord_id=”sciencemusicvideosMeister1961-DNA, RNA, and Nucleotides CFU”]
[h]DNA, RNA, and Nucleotides: Checking Understanding
[i]
[q] When parents pass genes on to their offspring, they’re doing it through the transmission of [hangman].
[c]IEROQQ==[Qq]
[q] DNA provides a kind of [hangman] that cells follow by making two other types of molecules: one is another nucleic acid called [hangman]; the second is [hangman] (a polymer of amino acids).
[c]IHJlY2lwZQ==[Qq]
[c]IFJOQQ==[Qq]
[c]IHByb3RlaW4=[Qq]
[q] In multicellular animals like ourselves, DNA also guides the pattern of [hangman] by which a fertilized egg develops into a multicellular organism.
[c]IGRldmVsb3BtZW50[Qq]
[q] The only place where RNA acts as the molecule of heredity is within the infectious particles known as [hangman].
[c]IHZpcnVzZXM=[Qq]
[q]Some RNA, like the RNA in a ribosome, acts very much like an [hangman], catalyzing the formation of chemical bonds. Other RNAs play a key role in controlling the [hangman] of DNA, which means controlling when DNA gets transcribed into RNA or translated into protein.
[c]ZW56eW1l[Qq]
[c]ZXhwcmVzc2lvbg==[Qq]
[q]The monomers of nucleic acids are called [hangman].
[c]bnVjbGVvdGlkZXM=[Qq]
[q]The sugar in DNA is [hangman]. The sugar in RNA is [hangman].
[c]ZGVveHlyaWJvc2U=[Qq]
[c]cmlib3Nl[Qq]
[q]Whereas DNA has the nitrogenous base thymine, RNA uses [hangman].
[c]dXJhY2ls[Qq]
[q]The three subparts of a nucleotide are a five carbon [hangman] (at “2”), a [hangman] base (at “4”) , and a [hangman] group (at “1”).
[c]c3VnYXI=[Qq]
[c]bml0cm9nZW5vdXM=[Qq]
[c]cGhvc3BoYXRl[Qq]
[q]DNA is the molecule of [hangman].
[c]aGVyZWRpdHk=[Qq]
[q]The flow of information in a cell starts with [hangman] in the cell’s nucleus. Then, the information in DNA is transformed into [hangman] which takes that information out to the cytoplasm. There, the information gets transformed into [hangman].
[c]RE5B[Qq]
[c]Uk5B[Qq]
[c]cHJvdGVpbg==[Qq]
[x][restart]
[/qwiz]
4. DNA and RNA Structure
Both DNA and RNA are nucleotide polymers.
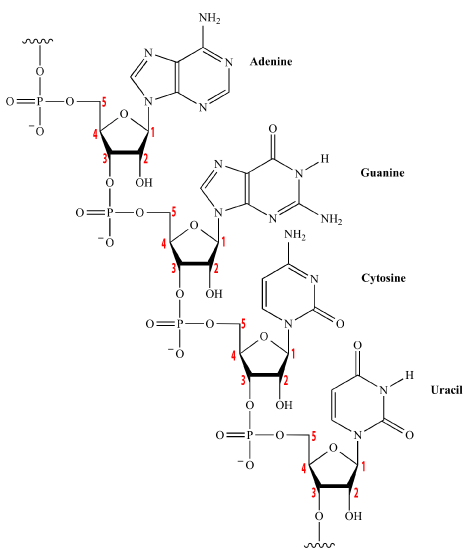
These polymers, at their most basic level, consist of strands of nucleotides connected in a linear sequence to one another by covalent bonds. You can see this in the diagram to your right, which shows all four of the RNA nucleotides chained together. Note that the sequence can be any combination, including repeats of the same nucleotide: that’s how nucleotides store and transfer information. The covalent bonds connecting the nucleotides have the following structure: the 5′ carbon of one nucleotide connects to that nucleotide’s phosphate group, and then that phosphate group connects to the 3′ carbon on the sugar in the next nucleotide. The bond connecting one nucleotide to the next is called a sugar-phosphate bond.
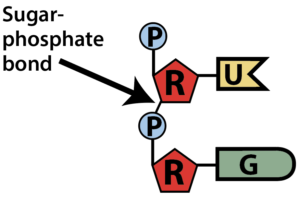
In a DNA or RNA polymer, the connected sugars and phosphates make up a sugar-phosphate backbone.
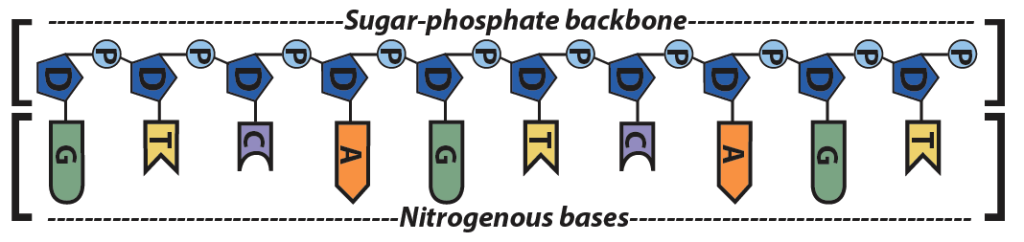
Another level of structure emerges from the shape and chemistry of the nitrogenous bases on DNA or RNA.
In DNA, the nitrogenous base adenine has a shape that’s complementary to the base thymine, and the base cytosine has a shape that’s complementary to guanine. In addition to their complementary shape, polar functional groups on these bases will form hydrogen bonds with one another. Three hydrogen bonds form between cytosine and guanine, while two bonds form between adenine and thymine.
| The dotted lines between complementary bases indicate hydrogen bonds | |
| Guanine-Cytosine | Adenine-Thymine |
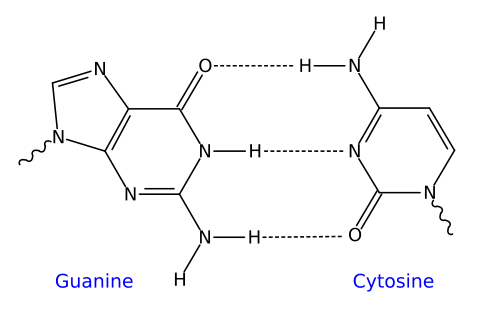 |
 |
Though it’s not shown in the diagram above (and often not shown in published diagrams) these hydrogen bonds only form when the nucleotides are positioned upside-down relative to one another, as shown below.
Adenine and Thymine |
Guanine and Cytosine |
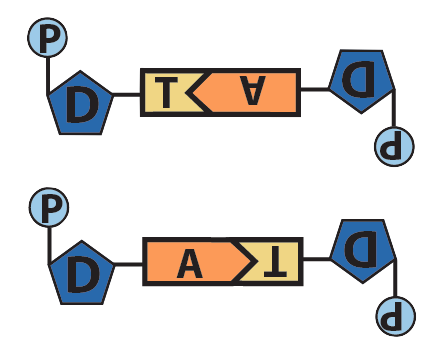 |
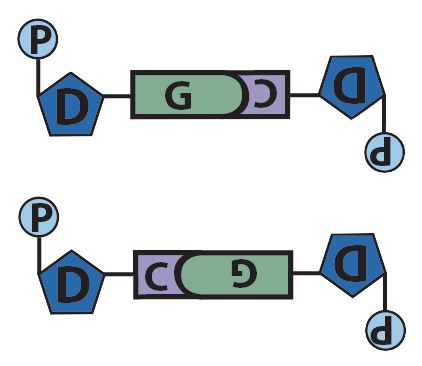 |
The result of this complementary base pairing is that DNA is typically double-stranded. Because the nucleotides in the two strands can form hydrogen bonds with one another only when they’re oriented upside-down relative to one another, the overall arrangement of the molecule is said to be antiparallel.
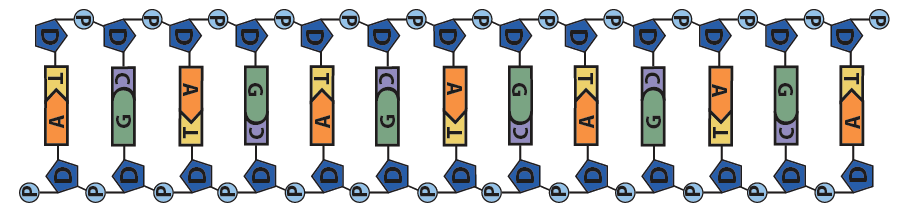
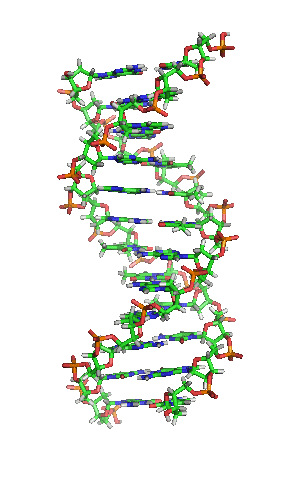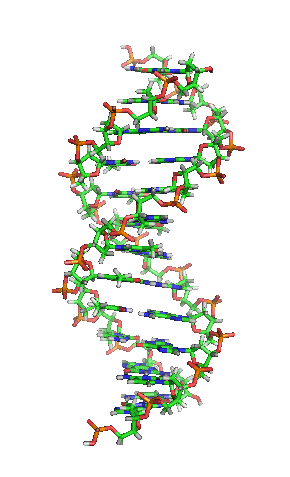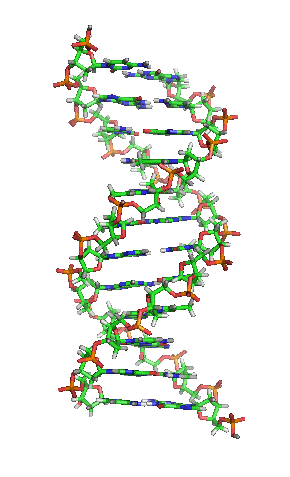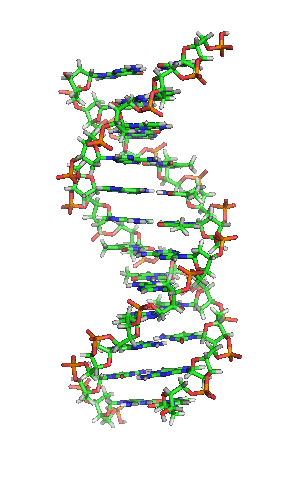
While it’s not shown immediately above, the bond angles between the sugar and phosphates twist DNA into its famous double helix formation. You can see a rotating version of a three-dimensional model of DNA in the top right of this page.
DNA’s double-stranded nature accounts for its ability to be the molecule of heredity, the stuff that genes are made of. The information in the genes is encoded in the sequence of the nucleotides. A change in that sequence can be enough to change the protein that a gene codes for. That can be disastrous and can be the cause of a genetic disease. The inherited blood disorder sickle cell anemia, for example, is caused by a single substitution of thymine for adenine in the gene for hemoglobin, the protein that carries oxygen in our red blood cells. Cystic fibrosis is most commonly caused by a deletion of three nucleotides.
DNA’s structure provides a way for DNA to be replicated. That allows DNA to be passed from one generation to the next, and to be passed from one cell to its daughter cells as an organism grows, develops, and repairs itself.
Here’s a big picture view of how DNA replication happens. Note that you’ll explore the details of replication in a later topic.
- In a series of reactions catalyzed by a team of enzymes, the two strands of DNA separate.
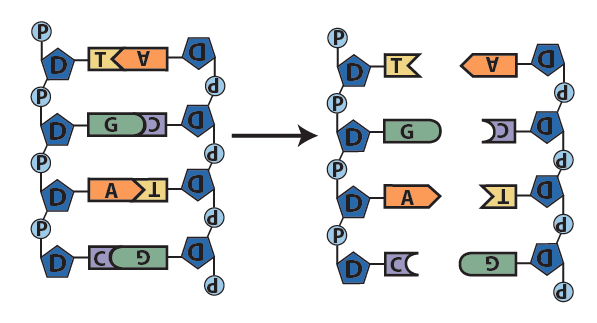
- With bases exposed, each single strand serves as a template for the synthesis of a new strand. Following the base-pairing rules, new complementary nucleotides form hydrogen bonds with nucleotides on the template strands.
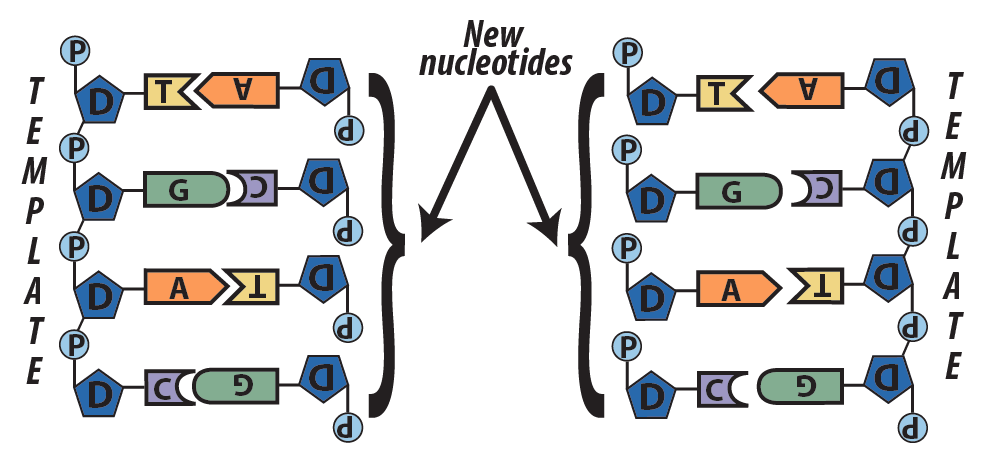
- Another team of enzymes seals covalent bonds between the sugars and the phosphates of adjacent nucleotides.
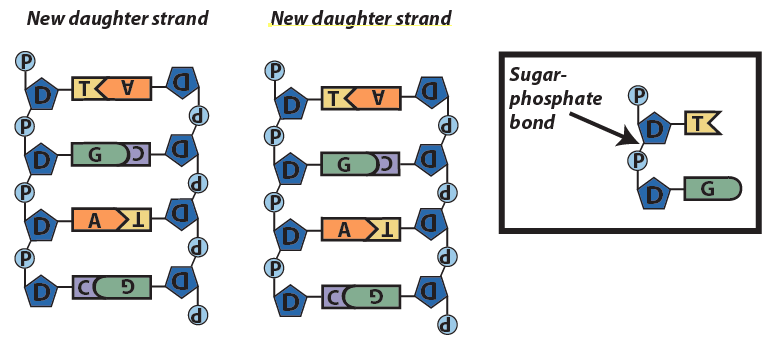
The enzymes that carry out DNA replication (and which transcribe RNA from DNA) can only add new nucleotides at the 3′ end of a growing strand. Later on in the course, we’ll see how this structures how DNA replication occurs. We’ll also see how this might be part of the reason why we’re not immortal, and why we succumb to diseases like cancer.
Complementary base pairing is also an essential part of RNA’s structure and function.
To begin with, the bases in RNA can form complementary base pairs with the bases in DNA. During a process called transcription, an enzyme called RNA polymerase opens up a stretch of DNA and uses the DNA as a template for making RNA. As shown in the table below, the base-pairing rules between RNA and DNA are almost the same as those used during DNA replication.
| DNA Base | Adenine | Thymine | Cytosine | Guanine |
| RNA Complement | Uracil | Adenine | Guanine | Cytosine |
Here’s a diagram showing the transcription of RNA from DNA.
Note how in transcription, as with DNA replication, new RNA nucleotides can only be added at the 3′ end of a growing nucleotide strand.
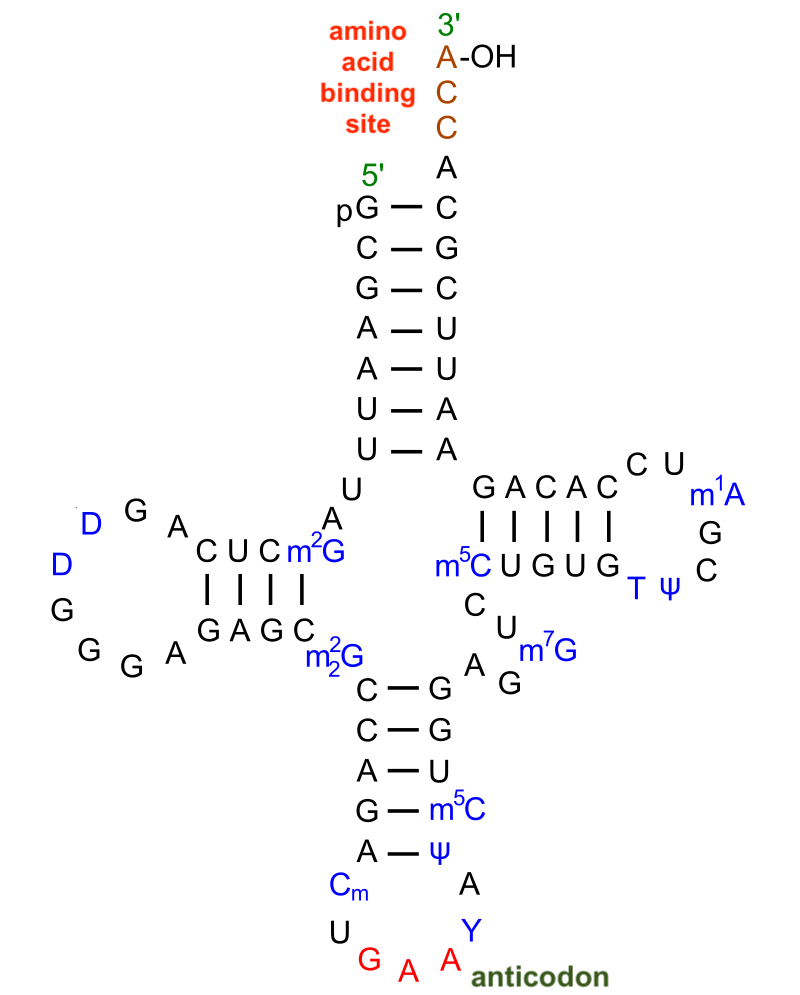
Base pairing plays a role in RNA structure in yet another way. RNA can serve as an action molecule because it can fold into complex three-dimensional shapes. This folding emerges from hydrogen bonding between nucleotides in the same molecule of RNA.
The molecule to the left is a transfer RNA. The letters represent the nitrogenous bases (A, U, C, and G) in an RNA nucleotide, with the sugars and phosphates left out (the letters in blue represent modified nucleotides). tRNA’s role is to bring amino acids from the cytoplasm to the ribosome. Its cloverleaf shape emerges from hydrogen bonds that form between adenine/uracil and guanine/cytosine pairs that come into proximity with one another, and which bond with one another with enough force to stabilize the molecule into this specific shape.
Other RNAs act as ribozymes: biological catalysts that are made of RNA (the “zyme” part of ribozyme refers to enzymes).
In biological systems, catalytic ability emerges from a molecule’s shape. In enzymes (which are proteins), that shape emerges from secondary, tertiary, and quaternary levels of structure, all of which are based on chemical interactions between the amino acids in a polypeptide. In the case of ribozymes, the interactions are from hydrogen bonds between RNA nucleotides. These can result in shapes as complex as the ones shown below, all of which give rise to these molecules’ catalytic properties.
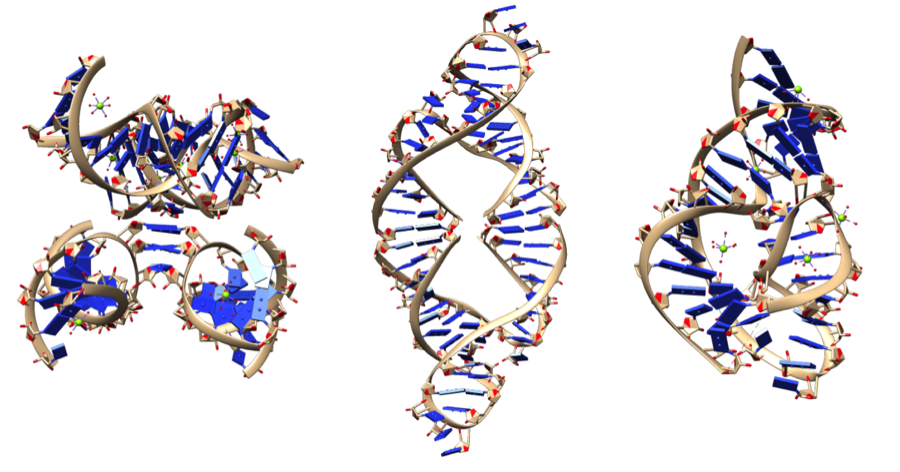
Nucleic Acid Overview: Checking Understanding
The purpose of this tutorial was to give you an overview of nucleic acids. Related modules in this course include DNA structure and replication, and how DNA controls the cell through transcription and translation.
But for now, let’s consolidate everything we’ve learned by taking a quiz.
[qwiz random = “true” qrecord_id=”sciencemusicvideosMeister1961-Nucleic Acids Overview”]
[h]Nucleic Acids: Checking Understanding
[i] Biology Haiku
Nucleic Acids
Information molecules
Transmission of genes
[q] Both DNA and RNA are nucleotide [hangman]. The bonds that connect the nucleotides are called [hangman]-[hangman] bonds (one of which is indicated by the arrow below).
[c]IHBvbHltZXJz[Qq]
[f]IEdvb2Qh[Qq]
[c]IHN1Z2Fy[Qq]
[f]IENvcnJlY3Qh[Qq]
[c]IHBob3NwaGF0ZQ==[Qq]
[f]IEdyZWF0IQ==[Qq]
[q] In the diagram below, the structure shown at “1” is the sugar-phosphate [hangman]. Connected to each sugar are nitrogenous [hangman] (shown at “2”).
[c]IGJhY2tib25l[Qq]
[f]IEdvb2Qh[Qq]
[c]IGJhc2Vz[Qq]
[f]IEV4Y2VsbGVudCE=[Qq]
[q] In the diagram below, the number that refers to the informational part of the molecule is
[textentry single_char=”true”]
[c]ID I=[Qq]
[f]IEV4Y2VsbGVudC4gSW4gbnVjbGVpYyBhY2lkcywgaW5mb3JtYXRpb24gaXMgc3RvcmVkIGluIHRoZSBzZXF1ZW5jZSBvZiB0aGUgbml0cm9nZW5vdXMgYmFzZXMsIHdoaWNoIGFyZSBzaG93biBhdCAmIzgyMjA7Mi4mIzgyMjE7[Qq]
[c]IEVudGVyIHdvcmQ=[Qq]
[f]IE5vLCB0aGF0JiM4MjE3O3Mgbm90IGNvcnJlY3Qu[Qq]
[c]ICo=[Qq]
[f]IE5vLiBJbmZvcm1hdGlvbiBpcyBzdG9yZWQgaW4gdGhlIHNlcXVlbmNlIG9mIG5pdHJvZ2Vub3VzIGJhc2VzLiBXaGljaCBudW1iZXIgcmVmZXJzIHRvIHRoYXQgcGFydD8=[Qq]
[q] The bonds between adenine and thymine below are[hangman] bonds.
[c]IGh5ZHJvZ2Vu[Qq]
[f]IENvcnJlY3Qh[Qq]
[q] The accuracy of DNA replication is based on the fact that adenine can only bond with [hangman], and cytosine can only bond with [hangman].
[c]IHRoeW1pbmU=[Qq]
[f]IENvcnJlY3Qh[Qq]
[c]IGd1YW5pbmU=[Qq]
[f]IEV4Y2VsbGVudCE=[Qq]
[q] In DNA’s double-stranded structure, the bases have to be oriented upside-down relative to one another to form hydrogen bonds. The name for the orientation of each strand relative to the other one is [hangman].
[c]IGFudGlwYXJhbGxlbA==[Qq]
[f]IEV4Y2VsbGVudCE=[Qq]
[q] In DNA, information is stored in the [hangman] of the nitrogenous bases.
[c]IHNlcXVlbmNl[Qq]
[f]IEdyZWF0IQ==[Qq]
[q] Whereas DNA uses the nitrogenous base thymine (along with adenine, cytosine, and guanine), RNA uses [hangman].
[c]IHVyYWNpbA==[Qq]
[f]IENvcnJlY3Qh[Qq]
[q multiple_choice=”true”] In the diagram below, which letter indicates one of the nucleotides that make up RNA?
[c]IA==QQ==[Qq]
[f]IE5vLiBIZXJlJiM4MjE3O3MgYSBoaW50LiAmIzgyMjA7QSYjODIyMTsgaXMgY2FsbGVkIGEgZGlkZW94eW51Y2xlb3RpZGUuIEl0JiM4MjE3O3MgYW4gYXJ0aWZpY2lhbCBudWNsZW90aWRlIHRoYXQmIzgyMTc7cyB1c2VkIGluIGJpb3RlY2hub2xvZ3kuIEl0JiM4MjE3O3MgbWlzc2luZyB0d28gb3h5Z2VuIGF0b21zIGNvbXBhcmVkIHRvIHJpYm9zZS4gTG9vayBhdCB0aGUgMiYjODI0MjsgYW5kIDMmIzgyNDI7IGNhcmJvbnMgb24gdGhlIHN1Z2FycywgYW5kIHlvdSBzaG91bGQgYmUgYWJsZSB0byB1c2UgdGhhdCBoaW50IHRvIGZpZ3VyZSBvdXQgd2hpY2ggbW9sZWN1bGUgaXMgYSByaWJvbnVjbGVvdGlkZSAoYSBtb25vbWVyIG9mIFJOQSku[Qq]
[c]IEI=[Qq]
[f]IE5vLiBIZXJlJiM4MjE3O3MgYSBoaW50LiAmIzgyMjA7QiYjODIyMTsgaXMgY2FsbGVkIGEgZGVveHlyaWJvbnVjbGVvdGlkZSwgYW5kIG9uZSBvZiB0aGUgbW9ub21lcnMgb2YgRE5BLiBJdCYjODIxNztzIG1pc3Npbmcgb25lIG94eWdlbiBhdG9tIGNvbXBhcmVkIHRvIHJpYm9zZS4gTG9vayBhdCB0aGUgMiYjODI0MjsgYW5kIDMmIzgyNDI7IGNhcmJvbnMgb24gdGhlIHN1Z2FycywgYW5kIHlvdSBzaG91bGQgYmUgYWJsZSB0byB1c2UgdGhhdCBoaW50IHRvIGZpZ3VyZSBvdXQgd2hpY2ggbW9sZWN1bGUgaXMgYSByaWJvbnVjbGVvdGlkZSAoYSBtb25vbWVyIG9mIFJOQSgpLg==[Qq]
[c]IE M=[Qq]
[f]IEZhbnRhc3RpYyEgJiM4MjIwO0MmIzgyMjE7IGlzIGEgcmlib251Y2xlb3RpZGUsIG9uZSBvZiB0aGUgbW9ub21lcnMgb2YgUk5BLCBidWlsdCBhcm91bmQgdGhlIDUgY2FyYm9uIHN1Z2FyIHJpYm9zZS4=[Qq]
[q multiple_choice=”true”] In the diagram below, which letter indicates one of the nucleotides that make up DNA?
[c]IEE=[Qq]
[f]IE5vLiBIZXJlJiM4MjE3O3MgYSBoaW50LiAmIzgyMjA7QSYjODIyMTsgaXMgY2FsbGVkIGEgZGlkZW94eW51Y2xlb3RpZGUuIEl0JiM4MjE3O3MgYW4gYXJ0aWZpY2lhbCBudWNsZW90aWRlIHRoYXQmIzgyMTc7cyB1c2VkIGluIGJpb3RlY2hub2xvZ3kuIEl0JiM4MjE3O3MgbWlzc2luZyB0d28gb3h5Z2VuIGF0b21zIGNvbXBhcmVkIHRvIHJpYm9zZS4gTG9vayBhdCB0aGUgMiYjODI0MjsgYW5kIDMmIzgyNDI7IGNhcmJvbnMgb24gdGhlIHN1Z2FycywgYW5kIHlvdSBzaG91bGQgYmUgYWJsZSB0byB1c2UgdGhhdCBoaW50IHRvIGZpZ3VyZSBvdXQgd2hpY2ggbW9sZWN1bGUgaXMgYSBkZW94eXJpYm9udWNsZW90aWRlIChhIG1vbm9tZXIgb2YgRE5BKS4=[Qq]
[c]IE I=[Qq]
[f]IEV4Y2VsbGVudC7CoCAmIzgyMjA7QiYjODIyMTsgaXMgY2FsbGVkIGEgZGVveHlyaWJvbnVjbGVvdGlkZSwgYW5kIG9uZSBvZiB0aGUgbW9ub21lcnMgb2YgRE5BLiBJdCYjODIxNztzIG1pc3Npbmcgb25lIG94eWdlbiBhdG9tIGNvbXBhcmVkIHRvIHJpYm9zZS4=[Qq]
[c]IEM=[Qq]
[f]IE5vLiAmIzgyMjA7QyYjODIyMTsgaXMgYSByaWJvbnVjbGVvdGlkZSwgb25lIG9mIHRoZSBtb25vbWVycyBvZiBSTkEuIFJpYm9udWNsZW90aWRlcyBoYXZlIHR3byBoeWRyb3h5bCBncm91cHMgYXR0YWNoZWQgdG8gdGhlaXIgMiYjODI0MjsgYW5kIDMmIzgyNDI7IGNhcmJvbnMuIFdoYXQgd291bGQgYmUgdGhlIHN0cnVjdHVyZSBvZiBhIGRlb3h5cmlib251Y2xlb3RpZGU/[Qq]
[q]In molecules like the tRNA shown below, the three-dimensional shape of the molecule is stabilized by [hangman] bonds that form between [hangman] nitrogenous bases (such as adenine and uracil).
[c]aHlkcm9nZW4=[Qq]
[c]Y29tcGxlbWVudGFyeQ==[Qq]
[q]In the diagram below, genetic information in the form of [hangman] (at “3”) gets transcribed into [hangman] (at “5”), which then goes to the cytoplasm where it’s translated by a ribosome into [hangman] (at “8”).
[c]RE5B[Qq]
[c]Uk5B[Qq]
[c]cHJvdGVpbg==[Qq]
[q]As shown below, information in DNA can be transcribed into RNA, which can start the process of converting information into action. This information transfer is possible because the bases in DNA are [hangman] to the bases in RNA.
[c]Y29tcGxlbWVudGFyeQ==[Qq]
[q]Whereas DNA is almost always [hangman] stranded, RNA is [hangman] stranded.
[c]ZG91Ymxl[Qq]
[c]c2luZ2xl[Qq]
[x][restart]
[/qwiz]
What’s next?
Proceed to the Biochemistry Cumulative Flashcards and Quiz, where you can review all of the biochemistry you’ve learned in this unit.